Nand2Tetris|Machine Language
结构
在传统计算机系统中:
CPU包括 ALU 和 一些通用寄存器,负责数学和逻辑运算、内存操作和控制操作
内存主要可以分为:程序和具体数据
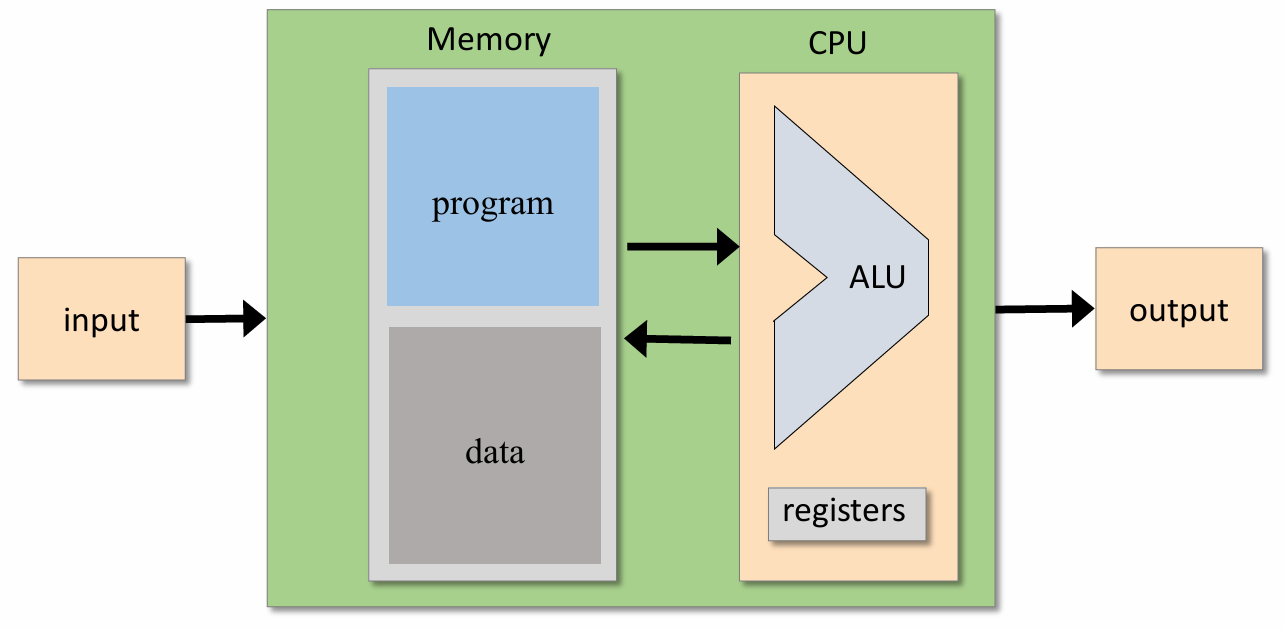
再具体来说,如下图
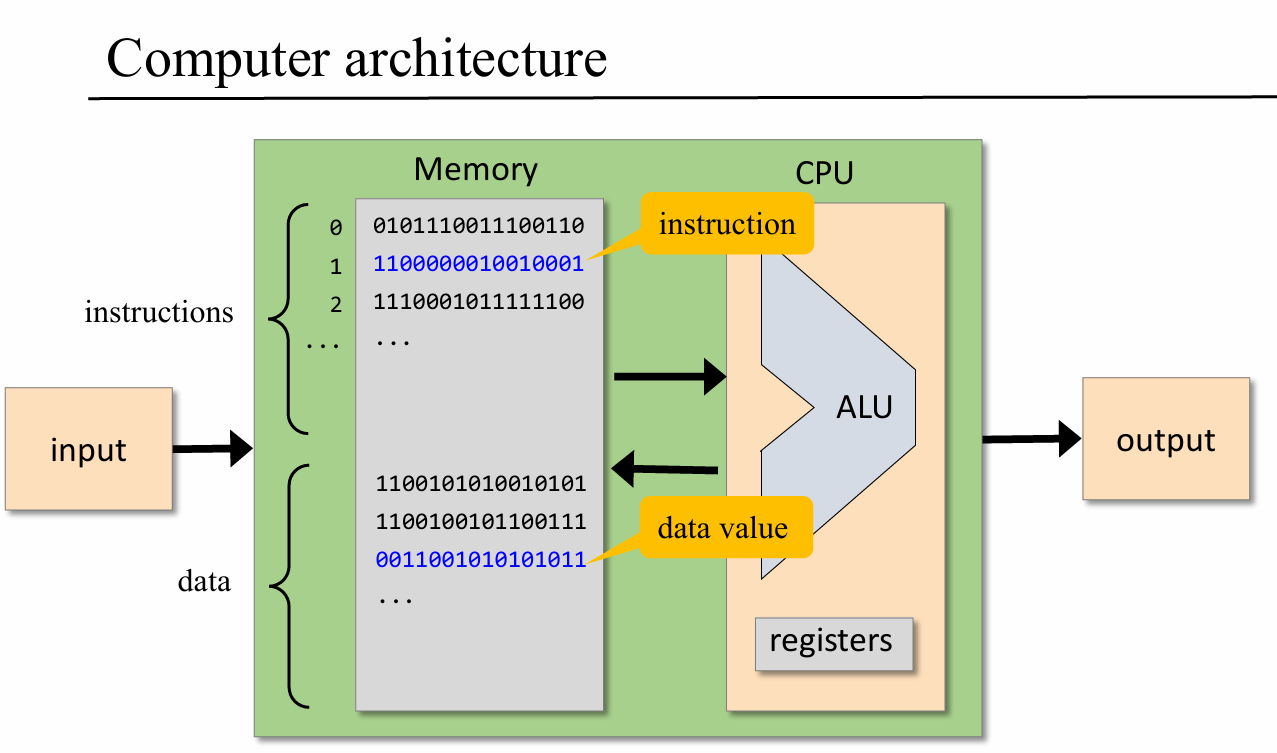
CPU操作寄存器,主要包括两大类:
- 归属于CPU的寄存器,一般直接通过名字访问
- 归属于内存的寄存器,一般需要通过地址进行访问
我们所说的机器语言,本质上其实只是一种控制CPU访问并且操作寄存器的形式
寄存器主要可以通俗的分为:
- 数据寄存器
Data registers - 地址寄存器
Address register - 指令寄存器
Instruction register
不同计算机的寄存器数量和寄存器大小(位宽)各不相同
不同计算机体系结构的机器语言,语义各不相同;但是他们的目的或者说作用场景都是一致的:访问并且操作寄存器
Hack Computer
基本结构
16 bit 的计算机,有两个存储单元,RAM 和 ROM
其中 ROM 是程序内存,只存储指令,只读
RAM 是数据内存,存储数据,可读可写
ROM 和 RAM 共同使用一个寄存器 A,这个寄存器可以用来存放地址也可以用来存放数据,本质都是16bit的数据
A基础指令
A指令用于写入地址寄存器,其中 @符号表示写入A寄存器,例如 @19 就表示向地址寄存器中写入19的数据,这样就会导致 ROM[A] 变得可见,同时 RAM[A] 也就是 M 也变得可见(可访达)
例如我们想要将 RAM[100] 中的数据写入到 RAM[200] 中,直观描述就是: RAM[200] <- RAM[100],可以使用如下的指令
1 | |
简单测试一下
Computes: RAM[2] = RAM[0] + RAM[1] + 17
1 | |
C指令实现条件跳转
在 Hack 指令中,实现跳转也是依靠组合指令,A指令来设置地址寄存器的数据,用于指示要跳转到哪一行程序指令
此后 ROM[A] 就会自动选择,通过 JMP 指令来实现跳转,跳转到 ROM 中指定位置的程序读取
例如 0;JMP 的语义就是跳转去执行 ROM[A] (也就是 声明 @ 之后自动选择到的)中指向的指令,其中开头的 0 是个无意义前缀

上图中的 D 可以替换为任意一种 ALU 可以计算的指令
例如 if(D=0) goto 300 的 hack 语言实现就是
1 | |
if(RAM[3]<100) goto 12
1 | |
变量声明
我们可以通过 @i 等任意非常量的方式,声明一个在我们广义上来看是变量的元素,编译器会将这个变量和对应分配的地址进行绑定,在 hack 语言的使用者来看,只需要每次向 A 地址寄存器中指定相同名称的非常量名,即可通过 M 访问这个变量在内存进行读写
例如:如下的高级语言代码
1 | |
在 hack 语言上
1 | |
Pre-defined Symbol in Hack
hack 中还存在 16 个内置的变量,我们有时也会称他们虚拟寄存器 R0 … R15
其实对应的就是 hack 系统中内存 0-15,只是更易于维护和编写 hack 代码
Labels
通过@也可以定义标签来实现某些兼容了低级语言的编程语言中 goto 表达式的效果
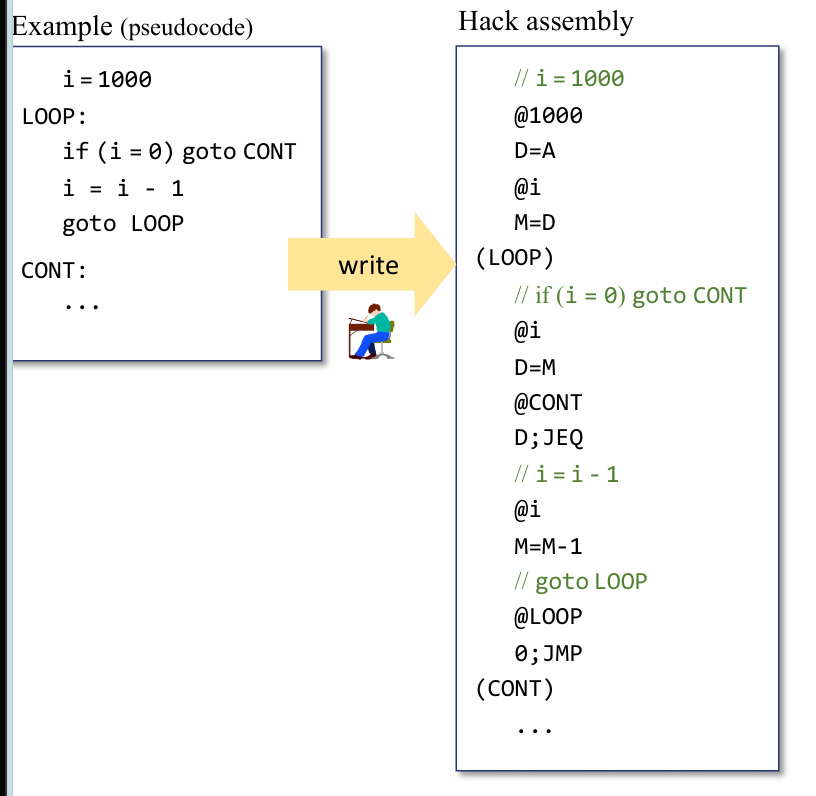
其实这里的 @CONT 或者是 @LOOP 可以等价于是变量定义的一种特殊声明,因为底层是汇编器去维护所有标签和对应所在的程序地址关系,hack语言编写者只需要@之后就会自动选择ROM[A]中对应的地址
Low Level Programming
Basic
综合上述的概念,我们现在对一段程序进行解析

除此之外,还有一个最佳实践:由于内存永远都不会是空的,因此需要在每一个汇编代码结束时设置死循环
1 | |
动手实践
1 | |
伪代码
1 | |
hack assembly
1 | |
Loop
这部分其实就是上一个部分的差不多内容,会基础部分就会这一个部分

Pointer-based processing
通过上面的描述也不难发现,如果想要实现类似指针的操作,其实就是将具体数值赋给 A 地址寄存器即可
例如下面这个需求
Sets RAM[R0] to –1 对应高级编程语言的 *p = -1,其中p指针的值就是R0
1 | |
上面的A=M 其实就是将 R0 中包含的内容作为地址
下面一句的 M = -1 则是将 RAM[A] 中的数据设置为 -1
Gets R1 = RAM[R0] 对应高级编程语言的 r1 = *p
1 | |
Array Processing
对于高级编程语言中数组的处理需要引入一个基础地址和 offset 的概念,其实也就是对应数组的起始分配位置和数组数据类型(每一个元素所占内存空间)
也就是数组类型的指针也会在内存中进行存储,而指针的具体位置我们并不关心,由编译器管理,指针包含的数据才是 arr 的实际地址
假设伪代码如下
1 | |
对应的 hack 语言如下:
1 | |
所有高级语言的数组访问表达式 arr[expression] 都可以编译成 Hack 代码,使用低级语法 A = arr + expression 来实现访问
Hack Language
C指令
一段完整的 C 指令包含三个部分,计算表达式comp,目的地dest,跳转jump,其实本文前面的部分都是在用到 C 指令,只是没有建立完整的概念
C指令的语义为:计算 comp 的值并将结果存储在 dest 中。如果 (comp jump 0),则分支执行 ROM[A]
例如:
- Sets the D register to -1 :
D = -1 - Sets D and M to the value of the D register, plus 1:
DM = D + 1 - If (D-1 = 0) jumps to execute the instruction stored in ROM[56]
- @56
- D-1;JEQ
- goto LOOP
- @LOOP
- 0;JMP
我们可以发现,C指令和A指令几乎都是成对出现的,在计算之前我们需要 A 指令来取地址,跳转之前也需要 A 指令来设置具体要跳转的内存地址
C 指令使用相同的地址同时访问数据存储器和指令存储器是没有意义的;所以给出的最佳实践是:C指令要么指定 M 要么指定跳转,不能同时指定两者
输入输出
处理输出和输出的方式有两个维度:
- 使用高级编程语言中提供的库
- 输出:用于处理文本、图形、音频、视频等的 I/O
- 输入:readInt, readString 等
- 低级层面:
- 输出:使用驻留在内存中的位图(bitmap)直接操作位
- 输入:直接读取裸 bit 数据
输出
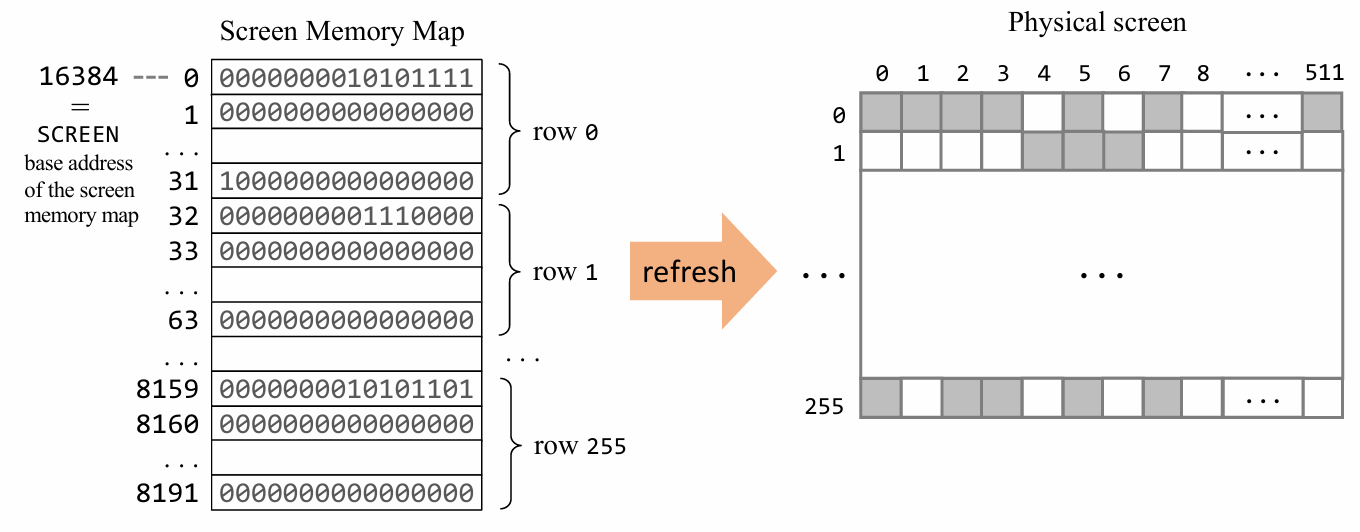
屏幕内存映射,其实就是将屏幕可以显示的像素,映射到内存中具体的地址位置:
一个 8K 内存块,专用于表示黑白显示单元,屏幕分辨率是 512*256。
基地址:SCREEN = 16384(在 hack 语言中是一个预定义符号 @SCREEN)
通过在屏幕内存映射map中写入指定的某个bit来呈现输出
由于 hack 中数据字长是16bit,因此屏幕上每一行的512个像素实际上对应内存中的 512/16 = 32行,如下图
给出几个样例:
将输出屏幕第一行的前16个bit设置为全黑(1)
1 | |
将输出屏幕的第三行(行号为2)的前16个bit设置为全黑
1 | |
输入
输入也有键盘内存映射,只需要分配 16 bit 的长度空间即可表示键盘的输入
也有一个预定义符号 @KBD = 24576
当按下键盘上的某个键时,该键的字符代码就会出现在键盘内存映射中,内存中 24576 地址的数据就是用户此时的输入字符对应 code (Hack 采用 Unicode)的二进制数据;例如 A = 65,键盘按下 A , RAM[KBD] = 65,当键盘没有按下任何按键的时候, RAM[KBD] = 0
如果用户输入了 q 则跳转到 END label 结束汇编程序
1 | |