CMU 15-213|Machine Level Programming-Procedure
基本流程
在机器指令实现过程调用(函数调用)的这个过程中,需要考虑的基本流程主要有下面三个:
- 传递控制:PC 变更,以及保留 PC 原始位置,return 要能回得来
- 传递数据:调用函数的时候形参的传递,以及 return value 的传递
- 内存管理:在调用函数的时候需要进行内存管理,函数 return 回来之后需要释放所占内存
X86-64的栈
X86中的栈本质上是一块内存区域,还记得我们之前介绍寄存器的时候一直在避开一个寄存器叫 %rsp 也就是 rigister stack pointer 他存储的是栈的栈顶指针

实际上它是一个倒过来的栈,地址越高说明在栈的越里面
pushq
我们假设当前 %rsp 指向的是红色位置
对于一个 push 操作,他的机器指令一般是
1 | |
主要完成的操作分为三步
- 读取 src 地址所指向的操作数
- 更新
%rsp += 8也就是栈的指针向下移动一个位置,用于存数据(此时 rsp 位置是在蓝色的位置) - 把操作数写入到
%rsp所指向的栈中位置里
popq
我们还是假设当前 %rsp 指向的是红色位置
对于一个 pop 操作,他的机器指令一般是
1 | |
主要完成的操作分为三步
- 读取此时
%rsp所指向的栈内的数据 - 更新
%rsp -=8也就是栈的指针向上移动一个位置,表示已经 pop 出了这个数据了,之前那个数据就不再记录了,要记录也是下一次覆盖了(此时 rsp 的位置是在黄色的位置) - 把之前读取的栈内的数据写入 dest 中(这里要求 dest 必须是一个寄存器)
调用详细流程
我们看一个最简单的例子,相乘两数之后存储到一个指定位置
1 | |
对应的机器代码为
1 | |
传递控制
在这个过程中,代码是如何跳转的,主要就是依靠 call 以及 ret 借助 stack 的隐式 push 和 pop 操作来实现程序的控制传递
初始状态在控制传递之前的一步,此时的 PC 指向的是准备进行调用函数的语句 call 那一段的地址

在调用 call Label 的时候会隐式的进行 pushq 的操作,这个时候 push 的数据是原先 PC 要更新的值,也就是 call 之后的下一条语句,我们进行入栈保存,如图栈顶数据以及栈顶的指针 %rsp 都得到了更新

之后执行调用函数的逻辑,准备返回外部函数的时候, PC 的指针已经指向了 return 语句

此时调用 return 语句,也会隐式地调用 pop 操作,将之前压入栈内的返回地址交给 PC ,同时也更新 %rsp 的指针位置,至此就完成了过程调用时控制传递,PC有去有回的效果

数据传递
下面需要回答之前提出的第二个问题,也就是在过程调用的时候,参数数据应该如何传递
在看到上面的汇编代码时我们也能总结出规律:
- 在参数少于六个的时候,用通用寄存器组(%rdi, %rsi, %rdx, %rcx, %r8, %r9 )来传递;大于六个参数的时候,多出来的参数会放在栈中存储
- 由于 caller 和 callee 都能正常访问到对应的寄存器,因此就是通过可见的通用寄存器来实现数据的传递
- 无论是外层函数还是被调用的内层函数,存储返回值的寄存器都是
%rax寄存器
内存管理(栈帧)
至于之前提出的第三个问题,机器级别的代码如何实现内存管理
市面上主流的基于堆栈的编程语言例如 Java 他们的代码就要求是可重入的,因为可能会出现多个单一程序的实例并发的进入
因此对于每一个实例需要有个地方去存储状态:
- 程序参数
- 本地变量
- 返回的指针信息
对于每个过程调用来说,都会在栈中分配一个帧 Frame
每一帧里需要包含:
- 返回信息
- 本地存储(如果需要)
- 临时空间(如果需要)
由于引入了帧的概念,也需要一个指针来记录当前帧的位置,当然这个是可选的,对应记录帧位置的寄存器就是 %rbp

每一个过程调用对应的栈帧都会在 call 的第一时间进行空间分配,在 return 返回的最后一刻进行回收
在 x86-64 / Linux 的栈帧中,基本的组成包含如下

下面我们进行举例
1 | |
这个被调用的函数 callee 的汇编很简单
1 | |
但是调用他的 call_incr 就不那么简单了
1 | |
对应的汇编是这样的
1 | |
逐步解析:
首先第一行,此时还是在 call_incr 的栈帧,栈帧中存储局部参数
注意图中 %rsp 指向的地址是调用 call_incr 的 caller 在 call call_incr 的下一步就设置好了的,它是属于 call_incr 栈帧的一部分,图里 ... 的部分才是栈中其他前面的函数的栈帧

第二行,这里是在进行 callee 的入参设置

之后通过 call label 的方式进行过程调用,返回值(根据上面的c代码,返回的是相加前的 value)存储在 %rax 中

下面就要结束 caller 的代码了,在 return 的最后一步,把栈帧抹去

Caller & Callee 寄存器一致性协调
通过上面的例子我们也可以发现
实际上在进行过程调用的时候,Caller 和 Callee 之间是通过彼此都可见的寄存器来进行参数传递的
因此在汇编代码中需要尽可能避免调用前后使用同一个寄存器的情况,因为此时作为入参的寄存器中数据可能已经在 Callee 中被修改了
同时也并不是所有的寄存器都可以用来存放临时的变量,因此需要某些规则或者说一致性的协商来实现
这也正是不同 ISA 之间函数过程调用之间的细小差异,只是在调用规则的一致性合约上进行了不同的规定,哪些寄存器用来传递参数,哪些存储返回值,哪些寄存器调用者/被调者可以放心使用(Caller Saved & Callee Saved)等,主要就是在这一块不一样
- Caller Saved 的寄存器
- Caller 在调用前在他的栈帧中可以保存临时值
- Callee Saved 的寄存器
- Callee 在使用前可以在他的栈帧中保存临时值
- Callee 可以在返回 Caller 之前恢复临时值
具体都有哪些呢?这个其实不是重点也不用记,简单看一下就好了,因为不会让你手写汇编的,实际上编译器也比你更聪明XD

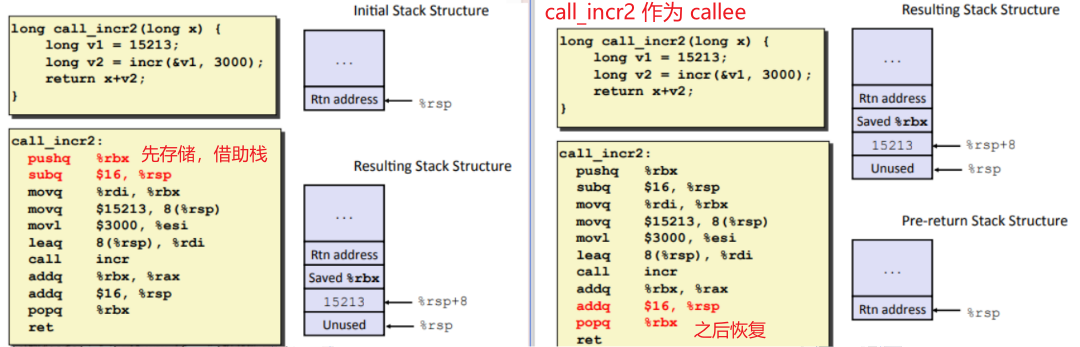
针对 callee saved 的寄存器,也有对应的例子,实际上我们可以理解为,它就是函数的入参,callee 可以对这个寄存器进行修改,但是原先传入的入参都需要保留和恢复
1 | |
递归
递归本质上也是一次特殊的过程调用
课件中的例子如下:实际上就是迭代式的 popcount 改写成了递归式的实现方式
1 | |
1 | |
下面我们就来分析这段代码例子
1 | |
这一部分其实就对应 x==0 的判断,很好理解