CMU 15-213|Machine Level Programming-Control
Condition Codes
概述
处理器有处理状态的标识符,在我们现在的处理器架构中就用这个状态信息来控制程序的运行,实现流程控制

状态码主要有四种,他们是实现程序运行或者流程控制最基本的条件,换句话说现在流程控制的执行本质上就是依据 condition codes 来进行的
我们需要注意的是这些寄存器:
- 临时数据主要放在 rax 中
- 运行时栈的地址存储在 rsp 中
- 代码的控制点程序计数器PC的数据存储在 rip 中
- 目前测试的指令最终设置的条件存放在 CF,ZF,SF,OF 中
基本状态码
- CF Carry Flag,操作结果进位时会设置他为 1,对应无符号运算的数据溢出
- SF Sign Flag,操作结果为负数时会设置他为 1,对应二进制数据的负数
- ZF Zero Flag,操作的结果为 0 值的时候设置他为 1
- OF Overflow Flag,操作结果溢出时会设置他为 1,对应有符号运算的数据溢出,例如两个正数相加得到负数,两个负数相加得到正数等
上面的四个基本状态码名称是在执行对应机器指令之后由处理器进行设置的,例如 addq
比如我们有一条类似于 t = a + b 的语句,在执行这个语句对应的汇编语句假设是 addq src dest
- 如果 a b 都是无符号,然后超出位数了溢出了,这个时候就会自动设置CPU的 CF位 = 1
- 如果 a b 都是有符号数,当
a < 0 & b < 0 & t > 0或者是a > 0 & b > 0 & t < 0的时候,就会设置CPU的 OF位 = 1
对于大多数的指令而言,执行操作的时候都会自动设置这四个 Condition Code,我们称这种设置 Condition Code 的方式为隐式设置
但是需要注意的是 leaq 这个指令不会设置状态码
Example
除了隐式设置 Condition Code 之外,我们还可以显式设置,主要有两个指令:
- cmp — compare 比较多个参数数据的值
- test — 用于测试相同参数
cmp
1 | |
相比于 add ,sub 这些会进行数据 set destination 的指令,cmp 只会进行比较,设置状态码,而不会 set destination.
什么是 set destination?
PPT 中很形象的进行了描述,对于汇编指令 add b, a 其语义可以简单理解为我们高级编程语言中的 a += b 也就是 a = a + b,这里进行了数据的赋值,对应处理器的 set destination 这个操作。
补充
教授提出了在 x86 系统中有两种不同的汇编语法顺序标准:
- intel / Microsoft 在使用的,我们不用
- Linux 采用的,我们用这个
Linux 采用的标准是反过来的,正如上面的汇编代码,因此我们在心里需要特别关注计算转换一下。

test
1 | |
和 cmp 一样,同样也是设置状态码但是不会设置任何的 destination
1 | |
一般我们是用两个相同的参数进行测试。
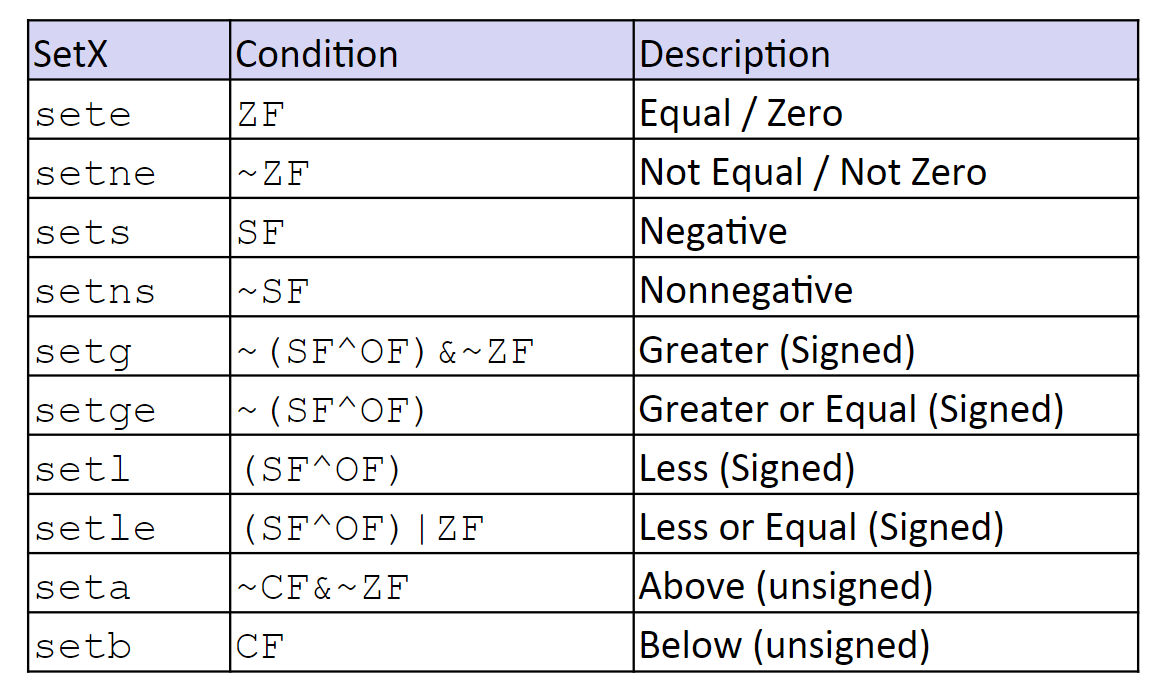
SetX Instructions
基本指令
上面其实都是在说状态码是如何得到的,那么状态码到底有什么用处呢?
教授介绍了一个 Set 指令,其作用在于 基于读取各种状态码的排列组合 来设置某个寄存器最低一位的 Byte 全为 0/1(也就是在 64 位的系统中前面七个字节都不进行修改)。
Example
那么 set 指令到底有什么用处,或者说 状态码 的存在到底有什么意义,我们可以看如下的 c 代码和汇编代码。
1 | |
我们假设编译器根据寄存器分配算法得到的各个变量以及对应寄存器如下:
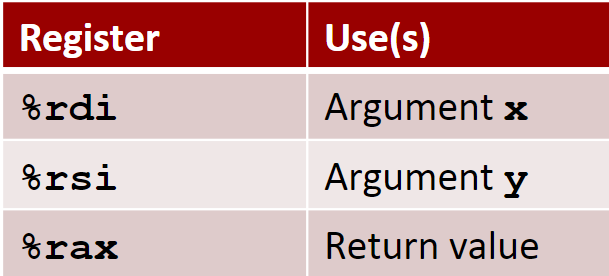
1 | |
对于 movzbl %al, %eax 这一段,教授进行了追加解释,%eax 引用的其实是 rax 寄存器的后 32 位也就是最后四个字节的数据,那么为什么说是设置其他七个字节都为 0 了呢(如何保证高位的 32 位呢),这主要与我们 x86-64 设计规则有关,当指令操作的结果是 32 位数据的时候,会自动填充高位 32 位为0
Conditional Branch
Introduction
上面一个部分通过介绍了状态码,以及如何基于状态码来设置寄存器的某一位结果,解读和实现汇编层面的比较 comparsion 操作
但是其实更多的时候我们想要的是实现复杂的条件逻辑,那么这在最底层设计也和状态码有关系。
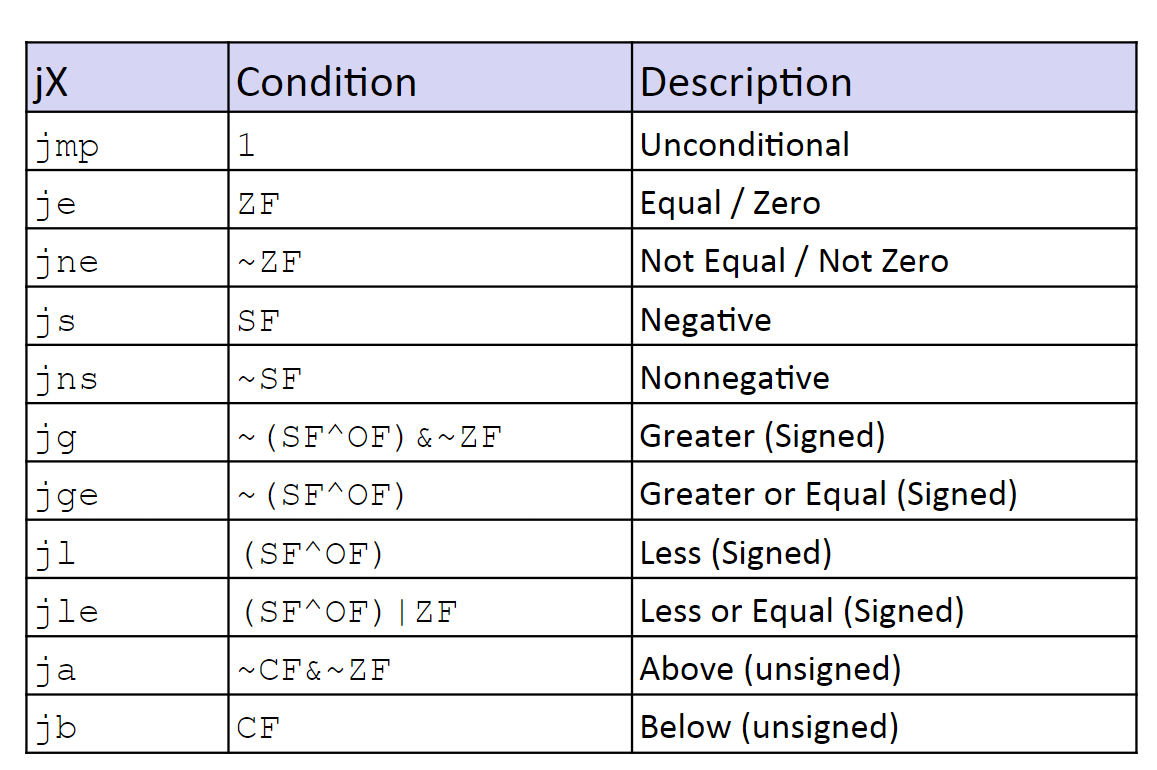
jmp
基本指令
jmp 指令是实现条件逻辑的最简单最朴素的一种汇编处理方式。
和 setX 一样, jmp 也是基于不同状态码的排列组合来实现程序不同代码段的跳转逻辑。
Example
1 | |
假设编译器通过寄存器分配算法得到了如下的表格
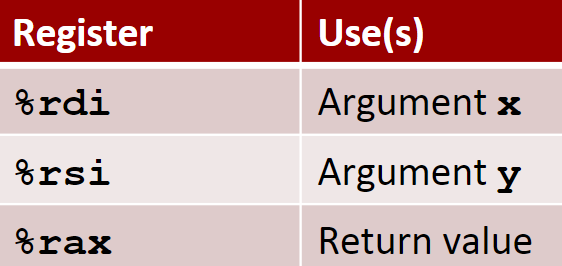
我们可以得到如下的汇编代码
1 | |
goto expression in C
这部分主要介绍 c 中不怎么常用,但是有助于我们理解汇编代码逻辑顺序的一个特性:go to 表达式
我们把 c 代码用 goto 语句重写一遍就更好看懂了,实际上 goto 语句的作用也就是更加贴近低级编程语言
对于上述的求两数之差绝对值的代码:
1 | |
如果用 goto 表达式改写,可以得到如下的结果:
1 | |
上面的 goto Else 其实就有点类似我们之前的 jle
Conditional Move & 初探编译器流水线和分支预测机制
核心理念
Conditional Move 不同于传统的 jmp 指令,他的核心思想在于 做所有的事情,直到最后才进行选择
对应分支预测也就是把所有可能的情况全部枚举出来,在最后才进行选择

?为什么这么做
教授进行了解释,实际上汇编出来的代码,并不是上述这样的,会采用另一种方法来加速分支语句的执行。因为这和编译器的分支预测有关系,关联 CPU 的流水线 (pipeline)机制
我们知道现在的 CPU 都是依靠流水线工作的,比方说执行一系列操作需要 ABCDE 五个步骤,那么在执行 A 的时候,实际上执行 B 所需的数据会在执行 A 的同时加载到寄存器中,这样运算器执行外 A,就可以立刻执行 B 而无须等待数据载入。
如果程序一直是顺序的,那么这个过程就可以一直进行下去,效率会很高。
但是一旦遇到分支,例如我们上面的例子,可能会出现 x 和 y 的值进入另一条分支的情况。那么就会导致执行完 A 下一步要执行的是 C。但是由于流水线机制的作用,此时寄存器中载入的数据是 B,这时候就要把流水线清空(因为后面载入的东西都错了),然后重新载入 C 所需要的数据,这就带来了很大的性能影响。
为此人们常常用『分支预测』这一技术来解决(分支预测是编译器的另一个话题这里不展开),但是对于这类只需要判断一次的条件语句来说,其实有更好的方法,这就是教授说的 Conditional Move 方式
处理器有一条指令支持 if(Test) Dest <- Src 的操作,也就是说可以不用跳转,利用条件代码来进行赋值,于是编译器在可能的时候会把上面的 goto 程序改成如下:也就是上图所描述的内容
1 | |
具体的做法是:反正一共就两个分支,我都算出行不行,然后利用上面的条件指令来进行赋值,这样就完美避免了因为分支可能带来的性能问题(需要清空流水线)
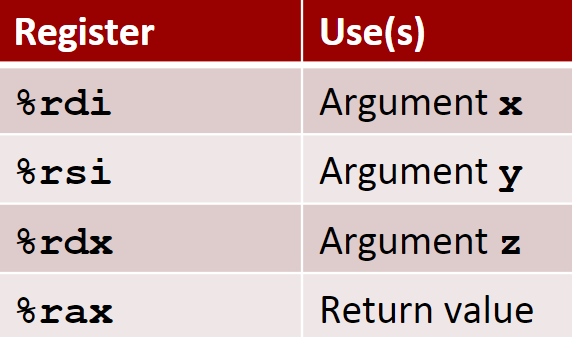
像下面这样,同样 %rdi 中保存了参数 x,%rsi 中保存了参数 y,而 %rax 一般用来存储返回值:
1 | |
正反面分析
当然 conditional move 也存在一些极端的效率低的情况,可以想象如果 test 和 !test 对应的情况都是很复杂的运算,或者是 test / !test 容易出错,那么 conditional move 就不是编译器最佳的选择
此外设计指针操作的时候,由于两个分支都会被计算,因此会出现不期望的结果
最后一种就是如果分支中的计算是有副作用的,例如 val = x > 0 ? x*= 7 : x+= 3;,这种情况下,因为都计算了同时都修改了 x 的值,那么最终这条语句执行完的 x 的值就不会再是我们期望的哪一个值了

Loops
如何理解Loops
Loops 本质上其实是 Conditional Branch 跳转的具体一个变体,本质上其实还是 jx 这些指令实现的。
do while
比如课件中一段经典的 popcount 代码,用于计算无符号整数中有多少位数据是1
1 | |
其对应的 goto 表达式如下:(便于理解汇编代码,其实 goto 表达式下的和最终的汇编代码框架上大差不差了)
1 | |
对应的汇编代码如下:
1 | |
所以我们可以得出如下的结论,针对 do while 语句,对应的汇编格式应该如下:
1 | |
while
针对 while 语句的转换,会直接进入到中间的 test 部分,如果不满足 tast case 就会直接顺序执行到 done 这一部分跳出循环,实际上一次也没有执行
1 | |
GCC的 O1 优化
值得一提的是,如果我们开启了编译器的 -O1 参数优化,那么编译器首先会将 while 语句翻译成 do while 语句,然后转换为对应的 goto 版本语句,最终 while 的汇编代码实际上就和 do while 的 goto 语句差不多了
灵魂三问:
- 什么是 O1 优化?
- 为什么需要 O1 优化,不这么优化可以吗?
- 还有没有更好的优化方式来实现等价或者类似的操作?
- 什么是O1优化
O1优化是 GCC 提供的多级优化方式中比较基础的一级优化方式。优化的内容主要侧重在流程控制,简化控制流,减少冗余代码等。
- 为什么需要,不这么优化可以吗
编译器的优化会改变代码的结构,默认情况下编译器是不会开启优化的,源代码是什么样,对应生成的汇编代码结构就是什么样。而开启优化后虽然不便于调试,但是性能方面提升了很多,优化级别越高性能的提升越大,在一些对性能要求严格的场景,例如实时嵌入式系统,大数据系统中,对于编译器的优化是十分需要的。
- 还有没有更好的
编译器优化等级还有更高的,代表更高的优化策略
此外还有**链接时优化 (LTO),Profile-Guided Optimization (PGO)**等方式
Switch Statements
CPU 分支预测压力最大的一集
三大特性
需要关注的是我们 c 中的 switch 语句主要有三大特性
- 可以存在多个标签匹配同一个 case 的情况(对应5&6)
- 可以存在没有 break 进行 fallthrough 的情况(对应2)
- 可以存在缺少 case 的情况(对应4)
1 | |
跳转表
由于 switch case 的语句一次判断可能会有多种可能的路径,这个时候 CPU 的分支预测压力就会很大,为了解决这一个问题, switch 在底层实现采用了一个很重要的数据结构 jump table
插一嘴:我们可以发现在计算机体系结构中,采用表来进行解决问题的方式很常见,例如分页表,回表,虚函数,甚至是算法中的 DP 这些都用到了表来实现
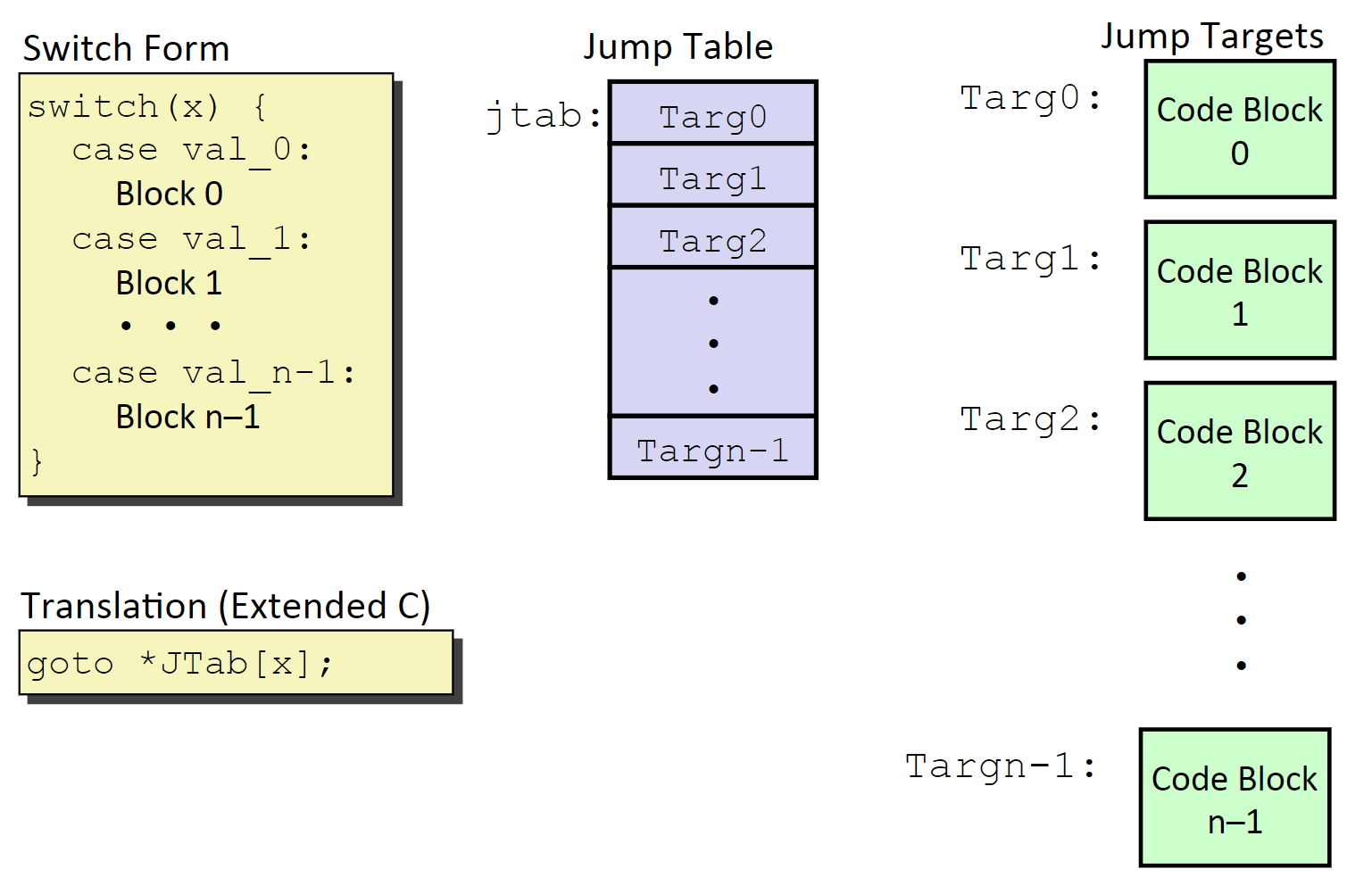
跳转表由编译器生成,汇编器进行填充,其中对于程序语句的 case 编号进行标号(比如图中的0 ~ n-1),我们根据这个编号可以构建出跳转表(上图的紫色部分)。
其实这个数据结构就是数组的基本实现,之所以这么做就是为了可以根据数组的随机访问特性 (Array Indexing) 通过 jump table 以 O(1) 的时间复杂度来快速定位具体的代码 block 数据段。
switch case 的汇编
我们可以看到课件中针对 switch 这段语句的整体框架生成的汇编代码如下:
1 | |
1 | |
跳转表为:
1 | |
之所以会将进行 case 比较的 x 和 6 进行比较是因为编译器在扫描了整段程序后,发现其实 case 的具体值的范围就落在 1~6 区间之间,因此此时会进行比较,通过比较来设置状态码。
但是这里的 ja 指令用的十分有说法, ja 是指 jump above ,和 jump greater 相比, ja 还考虑到了有符号负数的情况,如果 x 是一个负数的时候,通过 ja 进行比较,实际上比较的是 x 以无符号数形式来和 6 进行比较的,比较得到的结果其实是大于 6 的,直接跳到 default 的部分,而如果是 jg 则负数 x 是小于 6 的,那么还会进入 swich 体中错误的部分
因此课件中问的这个

其实表示的范围就是 (-∞,1]U(6.+∞] ,可以说这个指令用的非常的巧妙,很严谨
间接跳转
我们观察之前生成的汇编代码就可以发现,有一个带 * 的 jmp 指令,这就是间接跳转 indirect jump.
这里的意思其实就是通过间接跳转来以 O(1) 的时间复杂度根据 jump table 索引到具体的 case 段中。

直接跳转 jmp .L8,就直接跳到 .L8 所在的标签,也就是 x = 0
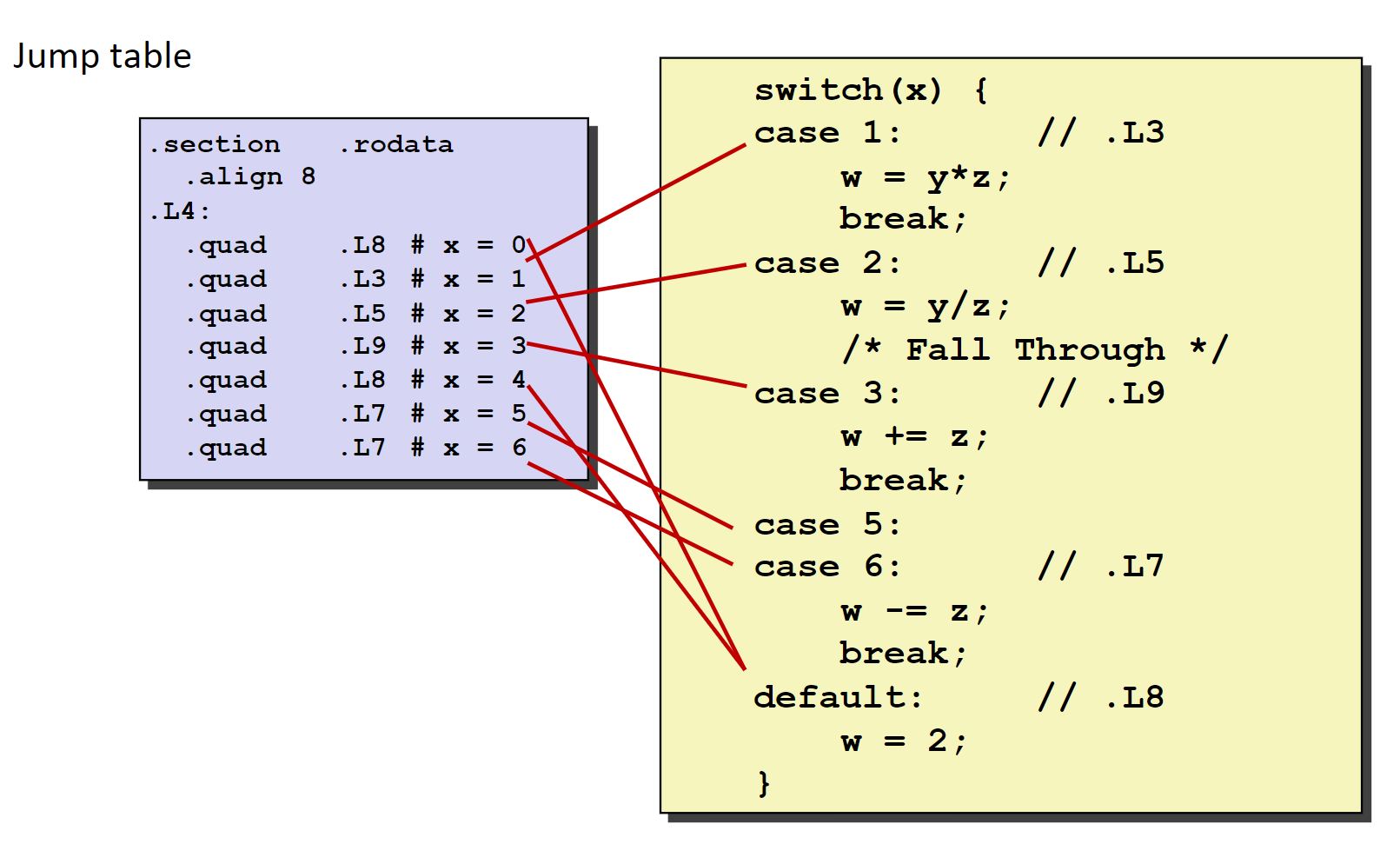
jmp *.L4(,%rdi,8) 那么就先找到 .L4 然后往后找 8 个字节(或 8 的倍数),于是就是 0~6 的范围
代码分析
下面我们来分段进行分析,还记得我们之前说的 switch 语句的三个特性吗,其实一开始的 demo 就很好地包含了这三个特性,看下生成的汇编代码到底是如何处理的。
最简单的无特性block:

下面是编译器 gcc 进行特殊处理的逻辑图
Fallthrough


多Case组合
