CMU 15-213|Machine Level Programming-Basic
History
Basics
首先我们需要有一个基本的概念。
程序运行的本质其实是机器响应程序而执行的一个个指令
主要可以分为这几种代码,我们需要有基本的概念
- 源代码(Source code):这个是我们用编程语言编写的程序源代码
- 汇编代码(Assembly code):编程语言的后端编译器Compiler会生成汇编代码。
- 目标代码(Object code):二进制机器码
Intel x86 Evolution
CISC的由来
以英特尔处理器为代表的计算机,是CISC(Complex Instruction set computer)。
与之对应的其实还有RISC(Reduce Instrction set computer)。
(其实一开始是没有CISC的,只是有了RISC之后,要贬低一下对方,才有了CISC XD)
为什么叫X86
关于处理器发展的历史,之所以习惯性的叫X86,其实也是历史遗留问题,因为最早的一代处理器是8086,后续处理器编号结尾都以86结尾,因此就叫做X86处理器。

分水岭
很关键的一处是在于2004年,Pentium 4E的型号,受限于处理器的功耗,Intel在2004起的处理器,不再增加时钟Clock的转速,因为发热量压不住,而是进行多核CPU的处理。
CPU指令
CPU的指令很多,并且不同的CPU型号支持的指令不尽相同(每一代CPU都会有新的指令支持),而指令本身会影响程序的执行,只需要记住这一点即可。
C Assembly & Machine Code
ISA
Instruction Set Architecture
简单来说就是在处理器设计中需要理解或编写汇编/机器代码的部分。
常见的ISA:
- Intel家的:x86, IA32, Itanium,X86-64
- ARM架构(手机,MAC)
CPU-Memory Architecture Overview

图中出现的都很重要
CPU
- PC:Program Counter 程序计数器————用于指令寻址,CPU的操作可以概括为取址执行
- Registers:寄存器————用于存储需要使用的数据,一般我们以名称来进行助记。
- 状态码:最近一些程序指令的结果,常用于进行条件转移,实现代码分支
Memory
- 可以看作是一个很大的字节数组。
- 操作系统实现的这个虚拟内存,这使得每个程序看起来似乎是有自己的一块独立内存用于程序访,可以实现每个程序共享同一块物理内存。
- CPU高速缓存?
Practice: c code to object code
这部分主要是熟悉一下gcc编译器的使用。
在正式的实践之前我们可以先看一下具体的代码,这个代码很典型,是最基础的求和并且存储到具体的一个值的案例。
1 | |
1 | |
-O参数表示 optimise 开启编译器的优化,而-S则表示 stop ,意思是说到了汇编代码就停止,只输出汇编代码(因为我们之前说了 gcc 编译器其实启动的是一系列的程序,不仅仅是生成汇编代码,同时还有生成二进制指令,linker 等程序。

我们可以得到如下的汇编代码。
1 | |
可以看到其实还是有一些所谓是 junk 的数据的,这一部分主要是由于我们的编译器进行标识定位所产生的,其实核心只需要关注ppt上的那部分代码即可。
1 | |
Assembly Characteristic
Data Type
这边主要简单声明一下汇编语言中的数据类型。
Integer 整数类型,汇编中我们可以操作的整数数据大小很多 1/2/4/8 字节的都有
- 值得注意的是在各大编程语言中的指针
pointer,本质上其实也是汇编语言的一个整数类型的数据,因为指针类型本质上是存储地址的,地址数据就是内存中具体的整型数值
- 值得注意的是在各大编程语言中的指针
Floating 浮点数类型,在机器级别中存储的比较特殊,使用的是另一组专用的寄存器
总结
- Assembly Code 每一条指令可以说所做的都很有限,不像是 go/java 的一些高级编程语言那样,可以一行代码做很多事情
- 同时汇编代码是没有
Array/struct这样的数据类型的,因为他们本身实际上是各大编程语言的汇编器所构建的上层建筑
Operations
汇编代码的操作其实是在 寄存器/内存数据 中进行算数运算的
汇编代码的运算其实更多的是从内存中获取数据,存储到寄存器中,或是从寄存器读取数据存到内存中
Object Code
由汇编器根据汇编代码生成目标代码(Object Code),都是二进制数据,之后需要由连接器进行连接(Link)装配运行时的静态代码库等
总结
其实本质上可以看成是如下的流程,我们用最常见的 c 语言指针运算的代码来阐述 movq 这个指令的作用

C代码中 *dest = t 的意思很简单,是将 t 的值赋到 dest 指针所指向的内存区域中
在这里对应汇编代码,有两个寄存器,分别是 rax 和 rbx ,对应代码中的 *dest = t,其中, t 的值在 rax 寄存器中,因此 %rax 就表示从寄存器中获取 t 的值
%rbx 的意思就是获取 rbx 寄存器里存储的 dest 指针存储的地址,(%rbx) 就表示在内存中找到对应的值,也就是 M[%rbx],在汇编代码中用小括号表示取地址
之所以要用 movq(Quad Word) 是因为整形数据都是 8 字节,对应是 4 个字(Word),因此 movq 就表示通过汇编代码操作寄存器中的数据写入内存
之后这段汇编代码被保存为 3 个字节长度的指令,存放在内存中 0x40059e 的地址位置
Disassemble
反汇编,很有意思的一个东西,其实早在我们开发应用的时候就接触过
比如IDEA(或者是JB全家桶的IDE)在导入依赖库的时候,有的时候我们是没有下载源码的,这个时候如果直接点进看没有本地源码的代码想看下实现逻辑,IDEA就会反汇编出原来的代码。但是我们常常会发现反汇编出来的变量名都是错乱的,比如var1,var2诸如此类的
这是因为反汇编仅仅只会计算 obj 代码的字节个数来得到结果,汇编的变量不可恢复,导致汇编反推源码的变量名也是不可恢复的
为什么反汇编后的变量名等都和源码不一样呢
这主要是因为在源码经过编译之后生成的汇编代码后,实际上变量名对于编译器是不关心的,他只会生成对应在哪一个 寄存器 中,而我们再根据这个汇编代码生成二进制的 object code 的时候实际上寄存器都是特定的,就那么多,因此对应的字节确实是可以反推,但是原先源码的变量名是不可以反推得到
反汇编工具
objdump -d (assembly code name)gdb (assembly code name)
小插曲
教授还说到了之前的课件中因为插入了Word执行文件的反汇编代码,收到了网友的谴责XD,这是因为在用户许可中一般都要求用户不能反汇编程序(当然也阻止不了你)
Assembly Basics
Registers
首先我们需要有一个基本的概念。
寄存器本质上其实是CPU中用来暂存指令,数据的一个存储单元,我们一般喜欢用名称的方式来对其进行记忆。
在PPT中列出了 8086 寄存器

其中rsp比较特殊,是stack pointer。
无论是32位还是64位都可以访问低位(reference low-order bytes),可以是低4字节,低2字节和低1字节。
向下兼容

其实这个图看的更加方便一点,我们可以看到图上对应不同的颜色以及不同的寄存器名称,黄色部分是 16 位寄存器,也就是 16 位处理器 8086 的设计,然后绿色部分是 32 位寄存器,给 32 位处理器使用,而蓝色部分是为 64 位处理器设计的。
这样的设计保证了向下兼容,也就是几十年前转为 16 位处理器开发的软件,如今也能在 64 位处理器上进行运行,因为寄存器中低位仍然保留
History
值得注意的是在x86之前的IA32指令集架构中,只有8个寄存器,而x86-64是有16个寄存器,相较于传统的 IA32 架构扩大了一倍寄存器的数量。

虽然说这里给出了各个寄存器的名字帮助记忆,但是其实这是之前的版本了,现在用什么寄存器和名字没有关系,只需要知道寄存器的名字是历史遗留问题即可。
Moving Data
一个很常见的经典指令movq(这里这个 q 是 quadword,对应64位)。
它支持很多操作量(operand)。
- Immediate
- 这个是指常量数据,比如某个常量地址/数值。
- Register
- 操作量可以是寄存器,这个比较常见。
- Memory
- 操作量还是可以内存地址,但是具体在寻址的时候存在两个模型,具体的寻址模式可以参见 [Simple Memory Addressing Modes](##Simple Memory Addressing Modes) 以及 [Compelete Memory Addressing Modes](#Compelete Memory Addressing Modes)
Combinations
一些和 movq 相关的指令组合
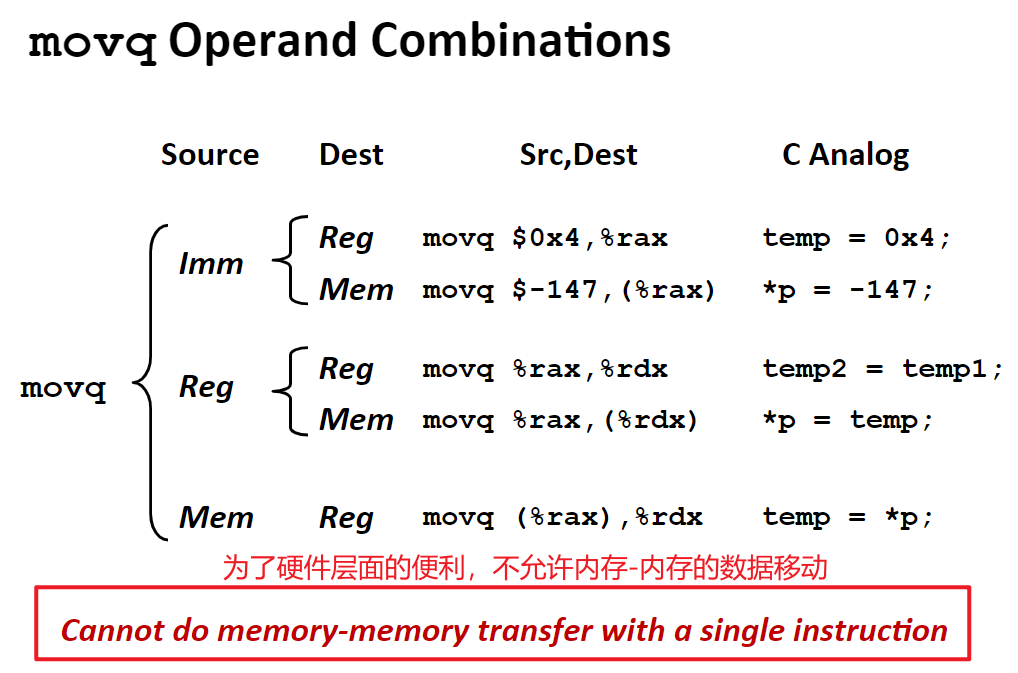
从上面的代码可以知道,其实寄存器中的数据完全可以看作是高级编程语言所编写程序中的 tmp 变量
Simple Memory Addressing Modes
Normal
最基本的寻址模式,通过一个括号。
(%rdx) 表示的是我们不关心 rdx 这个寄存器中的具体内容,直接就把他当作他存储了一段内存的地址,然后通过这个地址访问内存的数据。
说起来其实就等价于 c 中的指针寻址(referencing)。
1 | |
我们假设 temp 在编译器执行后得到的寄存器名称为 rdx ,而原始 p 指针的地址存储于 rax 寄存器,这段其实就等价于:
1 | |
再来看一个基本的例子,以著名的 swap 函数为例
1 | |
我们假设编译器在进行 寄存器分配算法 之后得到每个数据对应的寄存器如下表:
| Register | Value |
|---|---|
| %rdi | p |
| %rsi | q |
| %rax | i |
| %rdx | j |
则每一行的代码其实可以等价如下
1 | |
具体的图例如下




Displacement D(R)
偏移,存在一个偏移常量D。
常见的一个表示的形式就是 某个数(%rdx) ,表示的是对 rdx 这个寄存器内的地址进行偏移运算(具体运算就是加上这个数)
1 | |
以 %rbp 寄存器中存储的地址再加上 8 个偏移量去内存里找对应的数据,存到寄存器 %rdx 中
Compelete Memory Addressing Modes
最常见的就是在进行 数组引用 的时候。
具体的寻址相关符号定义如下:

其中的 Rb 其实就是一个基地址,对应我们数组的首个元素的地址,也叫做国内说的基址寄存器
而 Ri 则是存储具体元素在哪一个索引,对应的其实是我们数组元素的下标
S 则与数组的元素有关,之所以是 1|2|4|8 其实就是对应数组存储的不同数据类型所占据的字节长度(比如 int 是 4 个字节的长度)。
而 PPT 中也给出了一些基本的表示形式和运算规则:

上述的表达式不能死板的认为是一种只能用于内存地址的寻址方式,而是汇编语言通用的一种计算模板
实际上,它计算的只是一个整数值,可以用于多种目的
这种计算模板可以用于各种需要整数运算的场景,不局限于内存地址
lea
lea = load effctive address
uses
顾名思义其实就是加载内存地址,之所以会出现这个汇编的 operator 其主要的出现场景有两个:
1)就是我们 C 中的 ampersand 运算符 & 的汇编层面的对应,用来取地址
1 | |
2)许多 c 语言的编译器也很喜欢用 lea 去进行算数上的运算,等价于常数乘法
当使用 lea 进行算数运算的时候, leaq src dest 等价于将 src 的地址/值和 dest进行相加之后存储到 dest 所指向的寄存器中
这个第二点可以说有点违背直觉, leaq 通常用于计算内存地址,但它只是将一个计算结果存储在目标寄存器中。这个计算结果并不一定要用作内存地址,可以是任何需要的整数结果。这样,我们可以利用 leaq 指令进行一些高效的算术运算
example
课件中举出了如下的例子,这里就是利用 lea 进行算数运算上的优化
1 | |
对应的汇编代码在进行翻译解释后编译器得到的结果如下:
1 | |
Arithmetic Operations
教授还给出了其他一些常用的算数运算的操作符。


他们都有一个规律就是都以 operation src dest 的格式,有点类似我们高级编程语言中的 x+=y 这样的简写形式,因为 x+=y 其实就是 将 x 和 y 的值进行相加,之后又存储到了 x 中。
和 x+=y 类似, leaq src dest 也是将 src 的地址/值和 dest进行相加之后存储到 dest 所指向的寄存器中。
Arithmetic Expression Example
教授给出了如下的代码:
1 | |
要求我们可以看得懂哪些部分对应 c 中的代码即可,不要求你会写:
1 | |
所以对应的各个变量以及寄存器表格如下
| Arguments | Registers |
|---|---|
| x | %rdi |
| y | %rsi |
| z | %rdx |
| t1,t2,rval | %rax |
| t4 | %rdx |
| t5 | %rcx |