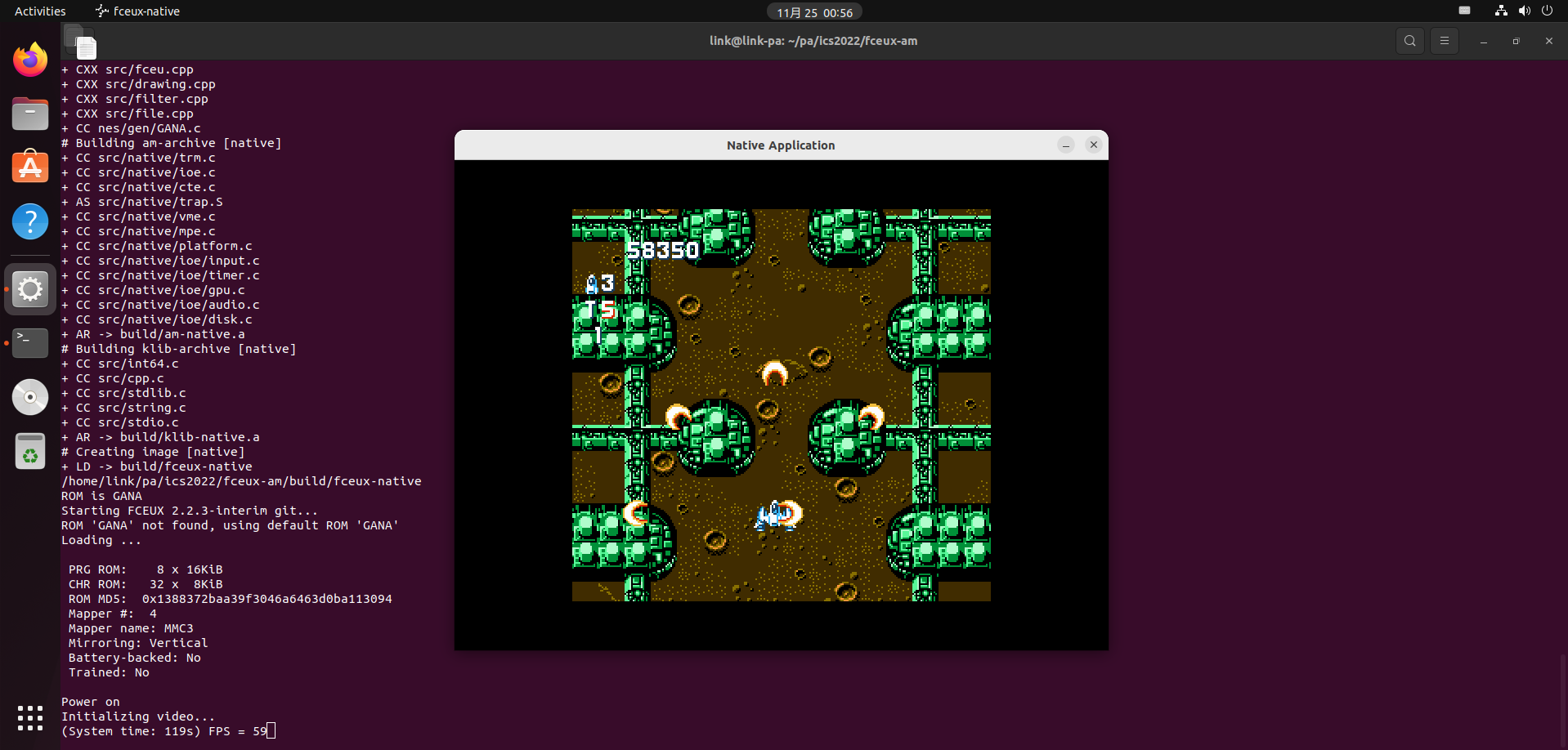
开始之前 NEMU是什么 首先我们需要知道我们这个实验真正需要做什么————实现一个 FC 模拟器(双 厨 狂 喜),他是一款经过简化的全系统模拟器。
NEMU 是基于开源的 FC 模拟器项目 FCEUX 移植而来,在之前 Lab0 的体验中其实我们已经装好了 FCEUX 这个项目的(同时官方也很贴心地为我们将其加入到了 .gitignore 文件中,可以进去体验一下,这里我们就以移植过后的 fceux-am 这个项目为例先进行一个 RTFM 初步跑起来一个 FC 游戏,至于游戏这块,我选择小时候最喜欢玩的 加纳战机 作为 ROM(仅为学习交流使用,不要问我哪里找的XD)。
初步的体验可以说是一切正常,而且不知道为啥总感觉 Linux 上玩画质更好(
运行的额外工作 检查按键 为了检查按键我们这里用一个讲义中同宫的新的子项目 am-kernels 来检查测试按键。
1 2 3 4 cd ics2022cd am-kernels/tests/am-tests
这个其实就是一个键盘 IO 的测试工具,按下什么就显示什么,感觉可以抽时间单独研究一下代码。
多线程编译 由于 makefile 默认是采用单线程进行编译的,因此编译构建的速度可能会比较慢,但是由于我们现在基本都是多核 CPU 的时代了,因此想要提升速度可以通过在 make 的时候追加 -j核心数 的这个参数来采用多个线程进行编译加快速度。
比如我这里是 2 core 的处理器,因此这里可以调动双线程进行编译加快速度。
同时为了查看到底加快了多少,我们可以在 make 命令的前面追加一个 time 命令,这个 time 会对我们 make 的时间进行统计
1 time make -j2 ARCH=native run mainarg=GANA
使用缓存进行编译加快速度 此外我们发现因为程序的源码本身没有改变,那么编译出来的结果大多数情况下也是不会发生改变的,那么我们是不是可以这样:如果发现编译的结果和之前一样,我们就直接取出来,不再进行长时间工程项目的编译。
这其实就是 缓存cache 的思想,在后续我们学习 CS 中会被广泛的运用上。
讲义中提到了 ccache 这个缓存库,我们可以安装进行体验一下。
所以NEMU到底是什么 讲义中给出了这三个例子进行比较,他们分别是
在GNU/Linux中运行Hello World程序
在GNU/Linux中通过红白机模拟器玩马里奥
在GNU/Linux中通过NEMU运行Hello World程序
1 2 3 4 5 6 7 8 9 10 11 12 13 +---------------------+ +---------------------+"Hello World" |"Hello World" | | NES Emulator | | NEMU |
针对 a 情况,GNU/Linux操作系统直接运行在真实的计算机硬件上, 对计算机底层硬件进行了抽象 , 同时向上层的用户程序提供接口和服务. 因此 Hello World 程序输出信息的时候, 需要用到操作系统提供的接口 。
而针对 b 情况,会有些复杂,实际上在 a 情况的基础上我们把 Hello World 更换为了 NES 模拟器,这个无可厚非,但是这个 NES 模拟器本身作为软件的同时还可以模拟出硬件。实际上对于马里奥来说, 它并不能区分自己是运行在真实的红白机硬件之上, 还是运行在模拟出来的红白机硬件之上 , 这正是”模拟”的障眼法。
那么再来看 c 情况,其实这个时候就很一目了然了,NEMU 本身其实也是和 NES 模拟器一样的存在,通过软件模拟出了一套硬件 ,并且在此基础上可以运行其它的软件系统。
选择ISA PA 为我们提供提供了三种不同的 ISA 架构,分别是:
具体选择的难易度如下表:(5星 - 容易, 1星 - 困难)
这里我们就直接选择 riscv 架构了,而且无论是哪一种架构,在学习的时候都是需要 RTFM 的。
什么是ISA 简单来说,我们可以把计算机硬件比作不同尺寸的螺丝钉 ,把不同架构的程序软件比作是不同尺寸的螺母 ,如果一个软件程序要在特定架构的计算机上个运行,那么这个程序必须要满足同一套规范 。
因此这里的一个规范其实就是 ISA,ISA的存在形式既不是硬件电路, 也不是软件代码, 而是一本规范手册。
和螺钉螺母的生产过程类似, 计算机硬件是按照ISA规范手册构造出来的 , 而程序也是按照ISA规范手册编写(或生成)出来的 , 至于 ISA 规范里面都有哪些内容, 我们应该如何构造一个符合规范的计算机, 程序应该如何遵守这些规范来在计算机上运行, 回答这些问题正是做 PA 的一个目标。
开天辟地的篇章 最简单的计算机组件 我们在程序设计这门课上其实都已经发现了,程序 = 代码 + 数据 . 数据是程序处理的对象,而代码则是代表程序如何处理这些数据。
讲义中引出了一个最简单的计算机执行最简单的程序的这么一个 demo 案例介绍了最简单的计算机所需要的一些硬件组件。
首先为了放程序,我们需要一个存储器 ,这个就是内存。程序加载进入了内存之后被 CPU 执行。
CPU 是计算机的大脑,负责处理数据的核心单元。
但是除此之外还是有点不太够,我们的 CPU 还需要运算器 ,对数据进行各种算术处理。
虽然说内存容量大,但是相比较于 CPU 的处理速度,还是比较慢 ,如果我们的程序需要对一个数据同时进行连续处理(比如一段程序求累加和的时候需要一个 sum 变量),我们就会需要寄存器 ,寄存器本身属于 CPU,它的定位和内存完全相反,可以装载的数据容量小,但是速度极快 ,让 CPU 把正在处理中的数据暂时存放在其中。
同时为了可以控制 CPU 做程序想要做的任何事情,我们还需要 指令 来指示 CPU 对数据进行怎样的处理。
自动化起来 有了指令之后,我们想着能不能让程序自动化地一行一行执行?显然这是可以的,因为我们的程序事实上就是自动地一行行执行的,我们来看下到底是底层通过什么来实现自动化执行的:
自动化执行其实就是执行完一条指令后继续执行下一条指令 ,那么计算机怎么知道现在执行到了哪一条了?因此我们需要一个特殊的计数器:PC (Program Counter) 程序计数器。
因此我们以后只需要把程序序列加载进入内存,然后让 PC 指向程序的第一行即可,整段程序执行的伪代码 大致如下
1 2 3 4 5 6 while (1 )
下面的指令序列可以计算 1+2+...+100, 其中 r1 和 r2 是两个寄存器, 还有一个隐含的程序计数器 PC , 它的初值是0
为了便于理解,右边那块是 c 代码。
1 2 3 4 5 6 7 // PC: instruction | // label: statement
我们可以发现上面的程序在计算完 100 之后就会一直停留在 pc5 这一指令中进入死循环,虽然是死循环,但是结果已经存放在了 r1 寄存器中,计算已经结束。
实验必做内容
在看到上述例子之前, 你可能会觉得指令是一个既神秘又难以理解的概念. 不过当你看到对应的C代码时, 你就会发现指令做的事情竟然这么简单! 而且看上去还有点蠢, 你随手写一个for循环都要比这段C代码看上去更高级.
不过你也不妨站在计算机的角度来理解一下, 计算机究竟是怎么通过这种既简单又笨拙的方式来计算1+2+...+100的. 这种理解会使你建立”程序如何在计算机上运行”的最初原的认识.
其实就是自己模拟一下上述的过程,我们可以发现本质上其实就是对应上述的工作方式:
最终将会进入图灵机的 halt 状态。
今天的计算机**本质上还是”存储程序”**这种天然愚钝的工作方式。
计算机是数组逻辑电路,如果从硬件视角来看,计算机本质上其实是由 时序逻辑电路(存储器,计数器,寄存器) + 组合逻辑电路(加法器)构成的,在每一个时钟周期到来的时候,计算机都会根据当前的时序逻辑状态,在组合逻辑电路组件的作用下,计算出下一时钟周期的新状态。
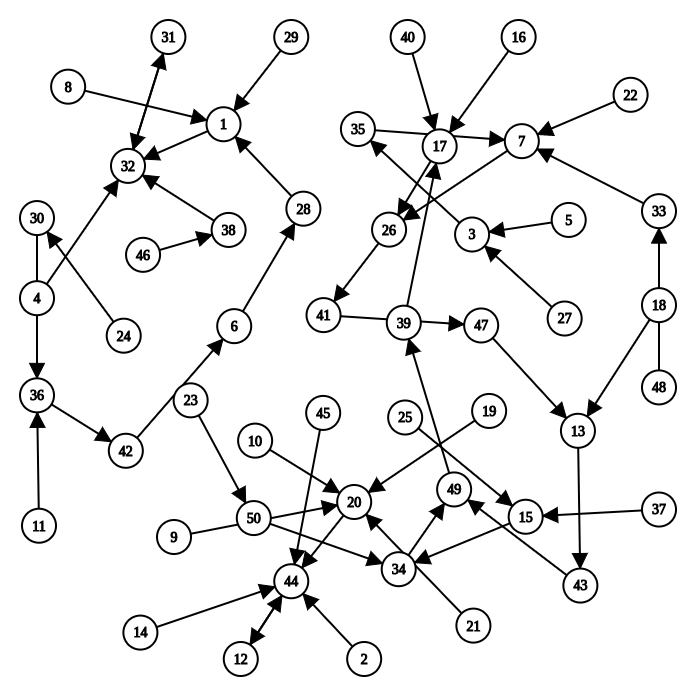
程序本质是个状态机 在讲义中假设了一个计算机有 4 个 8 位的寄存器, 一个 4 位 PC , 以及一段 16 字节的内存(也就是存储器), 那么这个计算机可以表示比特总数为 B = 4 * 8 + 4 + 16 * 8 = 164,因此总共的状态数 N 为 2 的164 次方。我们这里就简单地以 N = 50 来进行计算的话,也就是有五十种状态,一种可能的状态转移如下:
之所以会进行状态转移,本质上其实还就是因为每一段程序的执行本质上就会进行一次状态的转移。因此我们说执行程序的计算机本质上其实就是一个状态机。
完整的定义为:给定一个程序, 把它放到计算机的内存中, 就相当于在状态数量为 N 的状态转移图中 指定了一个初始状态, 程序运行的过程就是从这个初始状态开始, 每执行完一条指令, 就会进行一次确定的状态转移 . 也就是说, 程序也可以看成一个状态机! 这个状态机是上文提到的大状态机(状态数量为 N )的子集.
下面举个例子
假设某程序在上图所示的计算机中运行, 其初始状态为上图左上角的 8 号状态, 那么这个程序对应的状态机为
1 8 ->1 ->32 ->31 ->32 ->31 ->...
我们推测这个程序可能是:
1 2 3 4 5 // PC: instruction | // label: statement0 : addi r1 , r2 , 2 | pc0: r1 = r2 + 2 1 : subi r2 , r1 , 1 | pc1: r2 = r1 - 1 2 : nop | pc2: 3 : jmp 2 | pc3: goto pc2
实验必做内容:
以上一小节中1+2+...+100的指令序列为例, 尝试画出这个程序的状态机.
这个程序比较简单, 需要更新的状态只包括PC和r1, r2这两个寄存器, 因此我们用一个三元组(PC, r1, r2)就可以表示程序的所有状态, 而无需画出内存的具体状态. 初始状态是(0, x, x), 此处的x表示未初始化. 程序PC=0处的指令是mov r1, 0, 执行完之后PC会指向下一条指令, 因此下一个状态是(1, 0, x). 如此类推, 我们可以画出执行前3条指令的状态转移过程:
1 >(0 , x, x) -> (1 , 0 , x) -> (2 , 0 , 0 ) -> (3 , 0 , 1 )
请你尝试继续画出这个状态机, 其中程序中的循环只需要画出前两次循环和最后两次循环即可.
1 (0 , x, x) -> (1 , 0 , x) -> (2 , 0 , 0 ) -> (3 , 0 , 1 ) -> (4 , 1 , 1 ) -> (2 , 1 , 1 ) -> (3 , 1 , 2 ) -> (4 , 3 , 2 ) -> (2 , 3 , 2 ) -> (3 , 3 , 3 ) -> (4 , 6 , 3 ) -> ... -> (2 , 4851 , 98 ) -> (3 , 4851 , 99 ) -> (4 , 4950 , 99 ) -> (2 , 4950 , 99 ) -> (3 , 4950 , 100 ) -> (4 , 5050 , 100 ) -> (5 , 5050 , 100 )-> (5 , 5050 , 100 )...
RTFSC Overview 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 nemudef .hexec .c
这里官方把代码分为两大模块
与 ISA 无关的基本框架
不同 ISA 的具体实现
通过抽象不同 ISA 的接口以及在 nemu/include/isa.h 中进行装配不同的 ISA ,来实现适配不同的 ISA 支持。
配置系统与项目构建 配置系统 为什么需要配置系统 因为在一个完整的系统中,配置项可能会很多而且存在关联,我们需要一个系统来帮助我们自动化管理不同的配置以及修改配置后的关联修改 ,这个系统就是配置系统。
NEMU 的配置系统 NEMU 使用的是来自 GNU/Liunx 系的配置系统 kconfig,并进行了少量的简化操作,通过 kconfig 指定的描述语言,开发者可以在配置描述文件 中进行描述以下的几种配置:
配置选项的属性(比如某配置的类型以及默认值)
不同配置选项的关联依赖
配置选项的层级关系
个人感觉这一套配置描述下来,其实大概就是我们软件中用到的 setting 这么一个基本需求了。
NEMU 的配置描述文件为 nemu/Kconfig,当我们输入 make menuconfig 的时候,其实是通过 Makefile 自动化地帮助我们进行了配置描述文件的初始化 以及用户在此之后进行的配置设置 的整合 。
配置系统过程中需要注意的
上述的过程中会执行 mconf nemu/Kconfig 来通过解析 Kconfig 这个配置描述文件中的描述来生成展示各种用于用户设置的配置选项
在用户设置完毕之后会自动生成一个 .config 文件来持久化用户刚刚的配置选择。
配置系统在初始化以及用户配置持久化都完成之后,会执行 conf --syncconfig nemu/Kconfig 将配置描述文件 Kconfig 中的描述以及用户设置的结果 nemu/.config 进行结合,生成如下文件
可以被包含到C代码中的宏定义 #define (nemu/include/generated/autoconf.h), 这些宏的名称都是形如CONFIG_xxx的形式
可以被包含到Makefile中的变量定义(nemu/include/config/auto.conf)
项目构建Makefile NEMU 的 Makefile 很复杂,讲义中解析了他如下的几个功能
关联配置系统 我们上面提到了配置系统会结合初始化配置 Kconfig 的描述以及用户配置自动生成可以被包含到Makefile中的变量定义(nemu/include/config/auto.conf),因此如果用户通过 menuconfig 来进行配置的更新,Makefile 的变量也会发生改变,实现与配置系统的关联绑定。
文件列表filelist 在nemu/src及其子目录下存在很多名为filelist.mk的文件,这边以 nemu/src/filelist.mk 为例,我们先来理解一下这些文件的含义。
1 2 3 4 5 6 7 8 9 10 11 12 13 SRCS-y += src/nemu-main.c$(CONFIG_MODE_SYSTEM) += src/memory$(CONFIG_TARGET_AM) += src/monitor/sdb$(if $(CONFIG_TARGET_SHARE) ,1,0) $(if $(CONFIG_TARGET_NATIVE_ELF) ,-lreadline -ldl -pie,) ifdef mainargs"$(mainargs)\" endif SRCS-$(CONFIG_TARGET_AM) += src/am-bin.S .PHONY: src/am-bin.S
SRCS-y - 参与编译的源文件的候选集合SRCS-BLACKLIST-y - 不参与编译的源文件的黑名单集合DIRS-y - 参与编译的目录集合, 该目录下的所有文件都会被加入到SRCS-y中DIRS-BLACKLIST-y - 不参与编译的目录集合, 该目录下的所有文件都会被加入到SRCS-BLACKLIST-y中
同时我们也看到了 DIRS-BLACKLIST-$(CONFIG_TARGET_AM) += src/monitor/sdb 这种类似带有 $ 取值的操作,具体取的值是与 menuconfig 的配置结果中的布尔选项 进行关联。具体的工作模式是:
当我们配置系统自动生成了 nemu/include/config/auto.conf 之后,Makefile 中会关联该文件中定义的变量。
如果用户在 menuconfig 中选择了 TARGET_AM 相关的布尔选项时, kconfig 最终会在 nemu/include/config/auto.conf 中生成形如 CONFIG_TARGET_AM=y 的代码, 我们把变量进行带入展开后将会得到 DIRS-BLACKLIST-y += src/monitor/sdb ,对应其实就是将此文件夹加入黑名单备选。从而实现了在 menuconfig 中选中 TARGET_AM 时, nemu/src/monitor/sdb 目录下的所有文件都不会参与编译 .
如果用户在 menuconfig 中未选择 TARGET_AM 相关的布尔选项时, kconfig 将会生成形如 CONFIG_TARGET_AM=n 的代码, 或者未对 CONFIG_TARGET_AM 进行定义, 此时将会得到 DIRS-BLACKLIST-n += src/monitor/sdb , 或者 DIRS-BLACKLIST- += src/monitor/sdb , 这两种情况都不会影响 DIRS-BLACKLIST-y 的值, 因此 nemu/src/monitor/sdb 目录下的所有文件都会参与编译 .
编译和链接 讲义中指出对于类似的大型工程项目,Makefile的编译规则在 nemu/scripts/build.mk 中定义,我们可以看一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 .DEFAULT_GOAL = appifeq ($(SHARE) ,1)endif $(shell pwd) $(WORK_DIR) /build$(WORK_DIR) /include $(INC_PATH) $(BUILD_DIR) /obj-$(NAME) $(SO) $(BUILD_DIR) /$(NAME) $(SO) ifeq ($(CC) ,clang)else endif $(CXX) $(addprefix -I, $(INC_PATH) ) $(INCLUDES) $(CFLAGS) $(LDFLAGS) $(OBJ_DIR) /%.o) $(CXXSRC:%.cc=$(OBJ_DIR) /%.o)$(OBJ_DIR) /%.o: %.c$< $(dir $@ ) $(CC) $(CFLAGS) -c -o $@ $< $(call call_fixdep, $(@:.o=.d) , $@ )$(OBJ_DIR) /%.o: %.cc$< $(dir $@ ) $(CXX) $(CFLAGS) $(CXXFLAGS) -c -o $@ $< $(call call_fixdep, $(@:.o=.d) , $@ )-include $(OBJS:.o=.d).PHONY : app cleanapp: $(BINARY) $(BINARY) : $(OBJS) $(ARCHIVES) $@ $(LD) -o $@ $(OBJS) $(LDFLAGS) $(ARCHIVES) $(LIBS) clean: $(BUILD_DIR)
我们这里只关注具体的编译阶段
1 2 3 4 5 6 $(OBJ_DIR) /%.o: %.c$< $(dir $@ ) $(CC) $(CFLAGS) -c -o $@ $< $(call call_fixdep, $(@:.o=.d) , $@ )
确实是什么都看不懂,但是我们可以通过 make -nB 查看 make 过程中都执行了哪些操作:
可以看到很多形如如下的编译操作
1 gcc -O2 -MMD -Wall -Werror -I/home/link/pa/ics2022/nemu/include -I/home/link/pa/ics2022/nemu/src/engine/interpreter -I/home/link/pa/ics2022/nemu/src/isa/riscv32/include -O2 -DITRACE_COND=true -D__GUEST_ISA__=riscv32 -c -o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/timer.o src/utils/timer.c
我们可以知道
1 2 3 4 $(CC) -> gcc$@ -> /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/timer.o$< -> src/utils/timer.c$(CFLAGS) -> 剩下的内容
因此我们可以根据上述输出结果和Makefile反推 $(CFLAGS) 的值是如何形成的。
之后的链接过程,我们通过 make -nB 也可以看出
1 2 3 $(BINARY) : $(OBJS) $(ARCHIVES) $@ $(LD) -o $@ $(OBJS) $(LDFLAGS) $(ARCHIVES) $(LIBS)
1 g++ -o /home/link/pa/ics2022/nemu/build/riscv32-nemu-interpreter /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/nemu-main.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/device/io/map.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/device/io/mmio.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/device/io/port-io.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/cpu/cpu-exec.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/cpu/difftest/dut.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/cpu/difftest/ref.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/monitor/sdb/expr.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/monitor/sdb/sdb.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/monitor/sdb/watchpoint.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/monitor/monitor.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/rand.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/log.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/state.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/timer.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/memory/vaddr.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/memory/paddr.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/engine/interpreter/init.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/engine/interpreter/hostcall.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/logo.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/init.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/difftest/dut.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/reg.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/system/intr.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/system/mmu.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/inst.o /home/link/pa/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/disasm.o -O2 -O2 -lLLVM-14 -lreadline -ldl -pie