分布式系统数据复制模型(上)
前言
所有内容来自美团技术团队
Replication(上):常见复制模型&分布式系统挑战 - 美团技术团队 (meituan.com)
为什么需要进行复制
系统的扩展性
- 数据量读写负载增加,需要横向扩展
系统的可用性以及容错性(高可用)
- 单机故障在分布式系统中是常态,希望复制做到冗余备份,能够及时接管故障机器
统一的用户体验
- 多地部署服务,这个时候也是需要复制
复制的方式和目的
复制的方式
数据的多机分布的方式主要有两种:
一种是将数据分片保存,每个机器保存数据的部分分片(Kafka中称为Partition,其他部分系统称为Shard)
另一种则是完全的冗余,其中每一份数据叫做一个副本(Kafka中称为Replica),通过数据复制技术实现。
在分布式系统中,两种方式通常会共同使用,最后的数据分布往往是下图的样子,一台机器上会保存不同数据分片的若干个副本。这里主要探讨如何进行数据的复制

复制的目的
复制的目标需要保证若干个副本上的数据是一致的,这里的“一致”是一个十分不确定的词
从最终复制的结果来看,主要是有两种形式:
- 强一致性角度
- 任何时候不同客端都能访问到相同的新的数据
- 最终一致性,可用性角度
- 不同客户端某一时刻访问的数据不相同,但在一段时间后可以访问到相同的数据(强调的是最终能实现一致,但是具体什么时候,我不知道)
此时,大家可能会有疑问,直接让所有副本在任意时刻都保持一致不就行了,为啥还要有各种不同的一致性呢?
我们认为有两个考量点,第一是性能,第二则是复杂性。
性能比较好理解,因为冗余的目的不完全是为了高可用,还有延迟和负载均衡这类提升性能的目的,如果只一味地为了地强调数据一致,可能得不偿失。
复杂性是因为分布式系统中,有着比单机系统更加复杂的不确定性,节点之间由于采用不大可靠的网络进行传输,并且不能共享统一的一套系统时间和内存地址(后文会详细进行说明),这使得原本在一些单机系统上很简单的事情,在转到分布式系统上以后就变得异常复杂。这种复杂性和不确定性甚至会让我们怀疑,这些副本上的数据真的能达成一致吗?
数据复制模式
常见的数据复制模式主要有三种
- 主从模式
- 多Leader模式
- 无Leader模式
主从模式——最简单的复制模式
这是最简单的方式
核心思想在于赋予多个副本不同的角色
具体实现
我们常说主从架构中的主,是指主副本。主副本将数据存储在本地后,将数据更改作为日志,或者以更改流的方式发到各个从副本(后文也会称节点)中。
存在的问题
读取数据一致性问题无法保证
网络传输的时间开销不可忽略
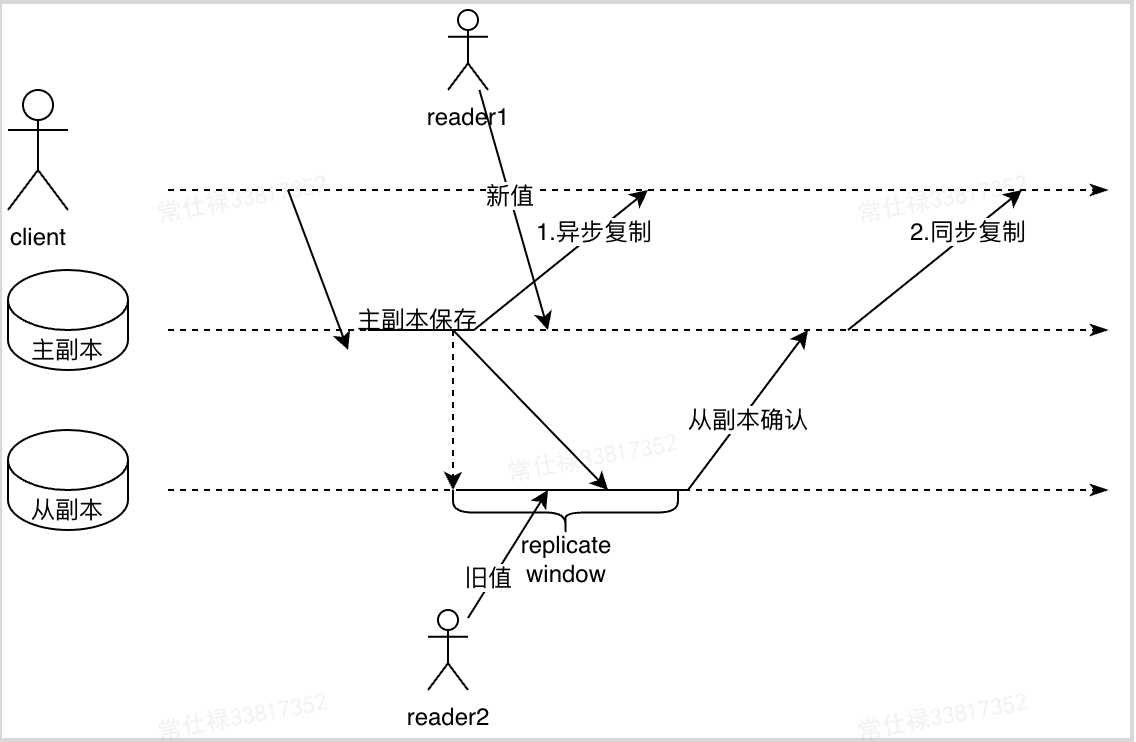
上述出现了异步复制和同步复制两种完全不同的复制方式(概念)
可能读到旧值,这个其实有专门的名称————复制滞后
这是因为在异步复制中,由于写请求写到主副本就返回成功,在数据复制到其他副本的过程中,如果客户端进行读取,在不同副本读取到的数据可能会不一致,《DDIA》将这个种现象称为复制滞后(Replication Lag),存在这种问题的复制行为所形成的数据一致性统称为最终一致性。
一致性的解决方式
两种做法可以参考
- Kafka当前的做法:所有客户端只能读主节点数据
- 采用同步复制的方式,任何一个副本同步的时候出现故障都会阻塞,同时要求每一次写请求都需要等待所有节点进行确认
还是有问题
- 所有读请求全部打入主节点,主节点故障切换时还是会有不一致问题
- 第二种方案:副本过多时系统吞吐量极低,消耗性能
很多系统都会采用半同步复制或异步复制来在可用性和一致性之间做权衡
需要的一些能力
追加新的从节点
- 在Kafka中,我们所采取的的方式是通过新建副本分配的方式,以追赶的方式从主副本中同步数据。
- 而经常使用的数据库,所采用的方式则是通过
快照(snapshot)+增量更新同步的方式来实现从节点数据的同步追赶,具体的操作实现步骤如下👇- 在某一个时间点产生一个一致性的快照
- 将快照拷贝到新创建的从节点
- 由于上述过程存在一定的网络传输时间,在这个过程中还存在一些增量更新,因此从节点会连接到主节点请求所有快照点后发生的改变日志
- 获取到日志后,应用日志到自己的副本中,称之为追赶
- 相比Kafka,数据库是将一段时间间隔内的数据抽取成了一个
snapshot的形式,之后多余的零散数据再进行追赶同步
处理从节点失效
这里一般采取的就是追赶式恢复
下面还是从两个具体应用角度来看
- 对于数据库而言,从节点可以知道在崩溃前所执行的最后一个事务,然后连接主节点,从该节点将拉取所有的事件变更,将这些变更应用到本地记录即可完成追赶。
- 对于Kafka而言,恢复也是类似的,Kafka在运行过程中,会定期向磁盘文件中写入
checkpoint,共包含两个文件,一个是recovery-point-offset-checkpoint,记录已经写到磁盘的offset,另一个则是replication-offset-checkpoint,用来记录高水位(下文简称HW),由ReplicaManager写入,下一次恢复时,Broker将读取两个文件的内容,可能有些被记录到本地磁盘上的日志没有提交,这时就会先截断(Truncate)到HW对应的offset上,然后从这个offset开始从Leader副本拉取数据,直到认追上Leader,被加入到ISR集合中
处理主节点失效
- 确认主节点失效,由于失效的原因有多种多样,大多数系统会采用超时来判定节点失效。一般都是采用节点间互发心跳的方式,如果发现某个节点在较长时间内无响应,则会认定为节点失效。具体到Kafka中,它是通过和Zookeeper(下文简称ZK)间的会话来保持心跳的,在启动时Kafka会在ZK上注册临时节点,此后会和ZK间维持会话,假设Kafka节点出现故障(这里指被动的掉线,不包含主动执行停服的操作),当会话心跳超时时,ZK上的临时节点会掉线,这时会有专门的组件(Controller)监听到这一信息,并认定节点失效。
- 选举新的主节点。这里可以通过通过选举的方式(民主协商投票,通常使用共识算法),或由某个特定的组件指定某个节点作为新的节点(Kafka的Controller)。在选举或指定时,需要尽可能地让新主与原主的差距最小,这样会最小化数据丢失的风险(让所有节点都认可新的主节点是典型的共识问题)——这里所谓共识,就是让一个小组的节点就某一个议题达成一致,下一篇文章会重点进行介绍。
- 重新配置系统是新的主节点生效,这一阶段基本可以理解为对集群的元数据进行修改,让所有外界知道新主节点的存在(Kafka中Controller通过元数据广播实现),后续及时旧的节点启动,也需要确保它不能再认为自己是主节点,从而承担写请求。